Wuyang's Tech Notes
Machine Learning Learning Projects
Cartoon Avatar Diffusion Model Memory Anatomy
by Wuyang Li
Following up the question "where has the GPU memory gone?" raised in the last section of the blog "build-avatar-diffusion-model-from-scratch". It's so puzzling to see that a relatively small model (~290M) with small input (~6M per batch) consumes almost the entire 24G GPU memory during training.
Trainable parameters of the avatar diffusion model is 76,464,439 (76 million), meaning that it's of similar size to Resnet152, which has 60 million parameters.
Components on GPU memory
As outlined in the huggingface blog -model memory anatomy, the components on GPU memory are the following:
- model weights
- optimizer states
- gradients
- forward activations saved for gradient computation
- temporary buffers
- functionality-specific memory
As shown in the screenshot of nvidia-smi on an AWS g5 2xlarge instance with 24G GPU memory, the training of the model consumes up to 22616 MB GPU memory. Among the components listed above, which is the top culprit?
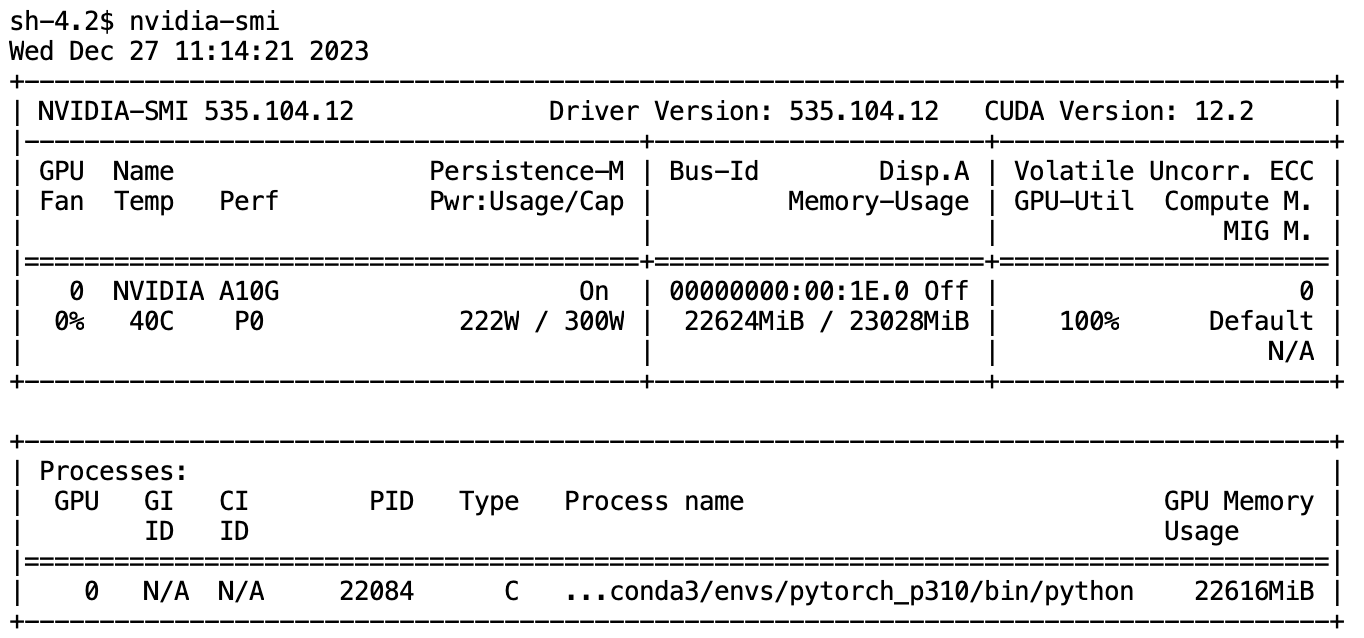
The Culprit
Model Weights, Optimizer and Gradients
the following table is a breakdown of model memory of weights, optimizer and gradients:
| memory breakdown | bytes per parameter | memory |
|---|---|---|
| model weight | 4 | 291.69 MB |
| adam optimizer | 8 | 583.38 MB |
| gradients | 4 | 291.69 MB |
As you can see, they're nothing compared to the total GPU consumption.
Forward Activations
How about forward activations that are saved for gradient computation?
According to the huggingface blog -model memory anatomy
size depends on many factors, the key ones being sequence length, hidden size and batch size.
There are the input and output that are being passed and returned by the forward and the backward functions and the forward activations saved for gradient computation.
I used the following function by ndvbd to estimate the activatio size of the avatar diffusion model:
# modified from https://discuss.pytorch.org/t/pytorch-appears-to-be-crashing-due-to-oom-prematurely/131039/13
# credit to ndvbd
total_output_elements = 0
def calc_total_activation_size(model, input_tensor_size):
"""
given the avatar diffusion model, calculate the activation memory in MB
"""
global total_output_elements
total_output_elements = 0
def hook(module, input, output):
global total_output_elements
if torch.is_tensor(output):
total_output_elements += output.numel()
# tuple output for attention modules
elif isinstance(output, tuple):
for o in output:
if torch.is_tensor(o):
total_output_elements += o.numel()
handle = torch.nn.modules.module.register_module_forward_hook(hook)
x = torch.randn(*input_tensor_size)
t_test = torch.randint(1, 10, (x.shape[0],)).float()
context_mask = torch.bernoulli(torch.zeros_like(c)+0.2)
result = model(x, c, t_test, context_mask)
handle.remove()
return total_output_elements*4/(1024*1024)
calc_total_activation_size(nn_model, (128, 3, 64, 64))
Voila! forward activation is the culprit! it consumes 18319 MB (~18G)
So why does such a small model (of 60 million params, ~290M in size) with small input (6M in size, 128 x 3 x 64 x 64 float tensor) generate 18G activation tensors?
The root cause is Convolution layers used in the network
Convolution blocks usually output large feature maps used as inputs to their following layers. In the case of Avatar diffusion model, in the downsampling path, the input tensors are transformed as follows:
[B, 3, 64, 64] -> [B, 128, 64, 64] -> [B, 256, 32, 32] -> [B, 512, 16, 16] -> [B, 1024, 8, 8]
As you can see, despite the exponentially shrinking width and height, the number of channels grows all the way from 3 to 128, 256, 512, and 1024. These tensors are all forward activations
[B, 128, 64, 64], [B, 256, 32, 32], [B, 512, 16, 16], [B, 1024, 8, 8]
As ptrblck explains in pytorch forum, conv layers usually require much larger activation size than its input, as opposed to other layers, eg. linear.
It really depends on the model architecture and especially for e.g. conv layers, you would see a huge memory difference, while linear layers could yield the inverse effect.
Here is a smaller example:
# conv
model = nn.Conv2d(3, 64, 3, 1, 1)
x = torch.randn(1, 3, 224, 224)
out = model(x)
model_param_size = sum([p.nelement() for p in model.parameters()])
input_size = x.nelement()
act_size = out.nelement()
print('model size: {}\ninput size: {}\nactivation size: {}'.format(
model_param_size, input_size, act_size))
model size: 1792
input size: 150528
activation size: 3211264
# linear
model = nn.Linear(1024, 1024)
x = torch.randn(1, 1024)
out = model(x)
model_param_size = sum([p.nelement() for p in model.parameters()])
input_size = x.nelement()
act_size = out.nelement()
print('model size: {}\ninput size: {}\nactivation size: {}'.format(
model_param_size, input_size, act_size))
model size: 1049600
input size: 1024
activation size: 1024
What we can do about it?
Now that we found the culprit for the GPU memory consumption, what can we do about it? When we run out of memory, there is a potential trade-off to make between memory and compute. Can we avoid saving activations? As explained in how activation checkpointing enables scaling up training deep learning models
Activation checkpointing is a technique used for reducing the memory footprint at the cost of more compute. It utilizes the simple observation that we can avoid saving intermediate tensors necessary for backward computation if we just recompute them on demand instead.
By applying activation checkpointing, despite a lower memory footprint, the training process is slower than without activation checkpointing.
References
A comprehensive guide to memory usage in pytorch
Relationship between memory usage and batch size
the huggingface blog -model memory anatomy
how activation checkpointing enables scaling up training deep learning models
tags: